f. HPCG & IOR metrics
In this section you will run the High Performance Conjugate Gradients (HPCG) Benchmark used to represent the computational intensity of a broad range of applications. Then you will run the IOR benchmark commonly used to evaluate storage performances on a system. The intent of this section is not to demonstrate the performances you can obtain on your system but visualize metrics for both applications. If you are interested in running IOR on Lustre with FSx for Lustre you will want to look at the Storage Lab
Install HPCG
-
First download and compile HPCG:
wget https://aws-hpc-workshops.s3.amazonaws.com/install_grafana_benchmarks.sh bash install_grafana_benchmarks.sh -
Next, create a submit file. You run over 8 nodes with a single core on each node. This establishes your baseline run:
cat > hpcg.sbatch << EOF #!/bin/bash #SBATCH --job-name=hpcg-job #SBATCH --nodes=8 #SBATCH --output=hpcg-run.out module load openmpi/4.0.3 mpirun --report-bindings --map-by core ${HOME}/hpcg/bin/xhpcg --nx 128 --ny 128 --nz 128 --rt 200 EOF -
Submit the job and monitor the queue:
sbatch hpcg.sbatch squeue -i 2 -
Once the job submitted it will be placed in a configuring state, noted CF in the
squeueoutput. After a couple of minutes, the job will change to a running state, noted R.
-
After the job completes, the HPCG output is stored in the
HPCG-Benchmark_3.1_2020-[date].txtfile that contains the timing information, scroll to the bottom and you’ll see:Final Summary::HPCG result is VALID with a GFLOP/s rating of=9.48102 Final Summary::HPCG 2.4 rating for historical reasons is=9.75306 Final Summary::Reference version of ComputeDotProduct used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeSPMV used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeMG used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeWAXPBY used=Performance results are most likely suboptimal Final Summary::Results are valid but execution time (sec) is=160.038 Final Summary::Official results execution time (sec) must be at least=1800
What are your observations when running HPCG? Look at the CPU usage, memory consumption and network throughput. Did you take a look at a particular instance?
Test with IOR
In the previous script we installed both IOR and HPCG. You will run both at the same time and see what the metrics tell you.
-
Start by creating submission script to run IOR:
cd $HOME cat > ior.sbatch << EOF #!/bin/bash #SBATCH --job-name=ior-job #SBATCH --nodes=8 #SBATCH --output=ior-run.out module load intelmpi mpirun /shared/ior/bin/ior -w -r -o=/shared/test_dir -b=256m -a=POSIX -i=5 -F -z -t=64m -C EOF -
Then your job to run IOR
sbatch ior.sbatch sbatch hpcg.sbatch squeue -i 2 -
After HPCG completes take a look at the timing file
HPCG-Benchmark_3.1_2020-[date].txt:Final Summary::Reference version of ComputeDotProduct used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeSPMV used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeMG used=Performance results are most likely suboptimal Final Summary::Reference version of ComputeWAXPBY used=Performance results are most likely suboptimal Final Summary::Results are valid but execution time (sec) is=156.78 Final Summary::Official results execution time (sec) must be at least=1800 -
What did you notice about the performance of both benchmarks? Take a look at the Compute Node Details dashboard and you will see IOR stressed the network with spikes looking like.
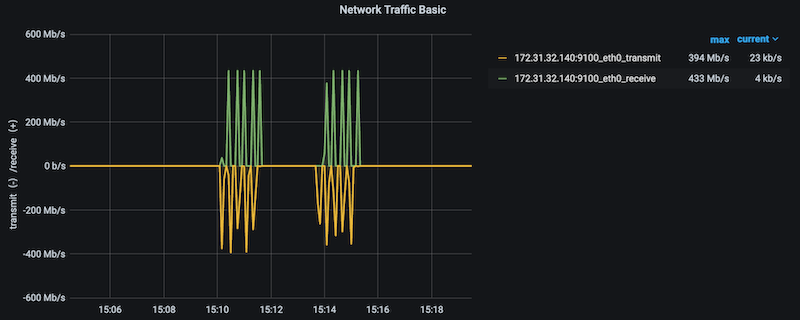
-
But did not stress the CPU:
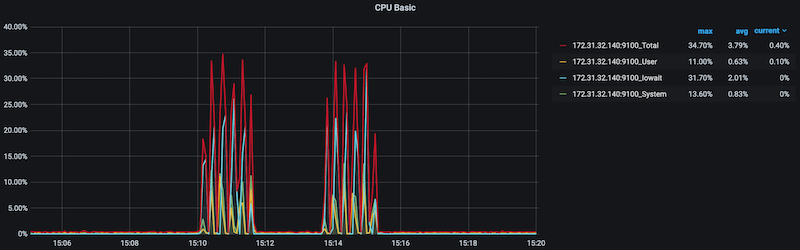
-
Now if you take a look at the metrics when you ran HPCG alone, you will observe a more of a constant load on the network with less spikiness.
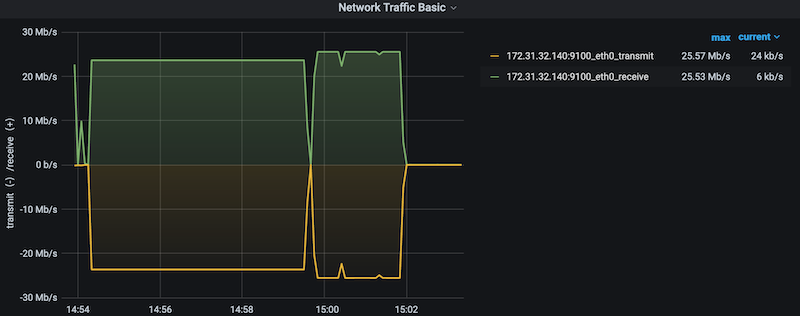
Did you take a look at the numbers of file descriptors opened when running IOR?