e. Download, compile and run the OSU Benchmark
In this section, you will download, compile and run a common MPI benchmarks from Ohio State University (OSU) .
Download and Compile the OSU Benchmarks
You can run the script below on the Master node of your ParallelCluster in the /shared directory
cd /shared
cat > compile-osu.sh << EOF
#!/bin/bash
module load intelmpi
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.6.2.tar.gz
tar zxvf ./osu-micro-benchmarks-5.6.2.tar.gz
cd osu-micro-benchmarks-5.6.2/
./configure CC=mpicc CXX=mpicxx
make -j 4
EOF
sh ./compile-osu.sh
Verify that the OSU-Benchmark is installed correctly
ll /shared/osu-micro-benchmarks-5.6.2/mpi/pt2pt/osu_latency
Submit OSU Latency benchmark
Create your job submission script for OSU Latency and use sbatch to submit your job:
cat > c5n_osu_latency.sbatch << EOF
#!/bin/bash
#SBATCH --job-name=osu-latency-job
#SBATCH --ntasks=2 --nodes=2
#SBATCH --output=osu_latency.out
module load intelmpi
srun --mpi=pmi2 /shared/osu-micro-benchmarks-5.6.2/mpi/pt2pt/osu_latency
EOF
sbatch c5n_osu_latency.sbatch
watch squeue
You have to wait a couple of minutes for your compute instances to come up, once you see the job go from PD pending to R running state, you know the instances are up. Type Ctrl-C to exit squeue at any point.
After the job has completed, find the output on /shared/osu_latency.out . Tail or cat this file, you will see something like this:
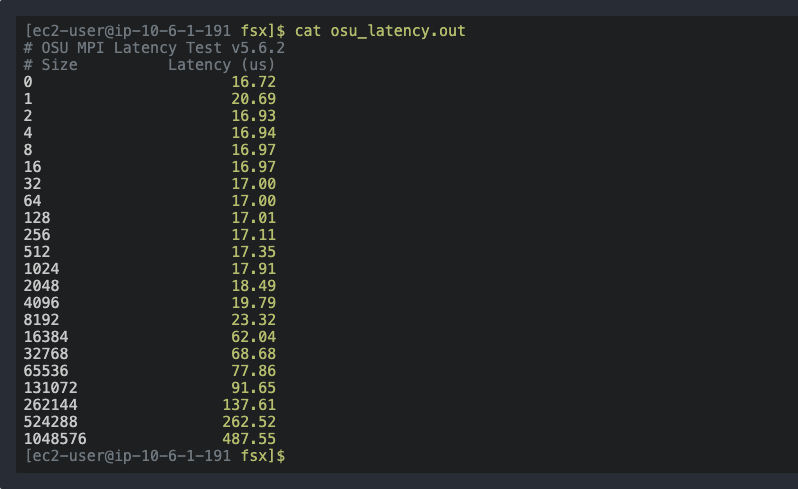
If EFA is configured correctly and you are running within a Cluster Placement Group, the latency between two EC2 instances will be ~15μs (Microsecond) Running the same benchmark on two non-EFA enabled instances will show around ~25μs (Microsecond), much hihger values if case not running on a Cluster Placement Group.
Submit OSU Bandwidth benchmark
Another benchmark you might want to run is the OSU Bandwidth.
cat > c5n_osu_bw.sbatch << EOF
#!/bin/bash
#SBATCH --job-name=osu-bw-job
#SBATCH --ntasks=72 --nodes=2
#SBATCH --output=osu_bw.out
module load intelmpi
srun --mpi=pmi2 /shared/osu-micro-benchmarks-5.6.2/mpi/pt2pt/osu_mbw_mr
EOF
sbatch c5n_osu_bw.sbatch
Below you can find an example output
[ec2-user@ip-10-0-1-178 shared]$ cat osu_bw.out
# OSU MPI Multiple Bandwidth / Message Rate Test v5.6.2
# [ pairs: 36 ] [ window size: 64 ]
# Size MB/s Messages/s
1 3.55 3553090.50
2 12.76 6381876.74
4 26.08 6519105.86
8 50.34 6292207.14
16 99.34 6208718.43
32 192.53 6016617.21
64 379.45 5928951.59
128 744.38 5815464.56
256 1460.41 5704732.62
512 2820.96 5509684.33
1024 5690.06 5556695.80
2048 9512.98 4645008.26
4096 11519.99 2812496.73
8192 11996.54 1464421.42
16384 11869.56 724460.26
32768 11861.97 361998.56
65536 11785.50 179832.45
131072 11917.45 90922.97
262144 12038.01 45921.37
524288 12188.34 23247.41
1048576 12156.93 11593.75
2097152 12113.78 5776.30
In the above example, once we reached a message size of about 4k, we acheived a multi-pair bandwidth of 12k MBps or 96.9 Gbps, roughly the 100Gbps bandwidth availible on c5n instances.