- Submitting jobs through cURL
You began interacting with the API to list jobs and partitions. Let’s take this exercise a bit further and submit a job by running the High Performance Conjugate Gradient (HPCG) Benchmark. Again without logging into the cluster head node. The job runscript that you will provide to sbatch is already stored on an S3 bucket. You can download it if you like to view its contents.
-
Run the following command to submit, compile and run HPCG.
curl -s POST "${INVOKE_URL}/slurm?instanceid=${HEAD_NODE_ID}&function=submit_job&jobscript_location=aws-hpc-workshops/run-hpcg.sh" -H 'submitopts: --job-name=HPCG --partition=compute' -
Once the job is submitted, you should see a message indicating that it has been submitted to Slurm and with its corresponding Job ID. List the jobs using the
list_jobsfunction to check its status.curl -s POST "${INVOKE_URL}/slurm?instanceid=${HEAD_NODE_ID}&function=list_jobs"The job script
run-hpcg.shdownloads and compiles the HPCG benchmark and then submits another batch job to run it. When you list jobs after a few mins as above you will notice another job submitted for the HPCG run (check the Job IDs) -
To get more details about your job, use the function
job_detailswhile replacing the<JOB-ID>string with the ID of your HPCG job.curl -s POST "${INVOKE_URL}/slurm?instanceid=${HEAD_NODE_ID}&function=job_details&jobid=<JOB-ID>" # Specify the JobId in the <JOB-ID> field -
You should see a result similar to the one below
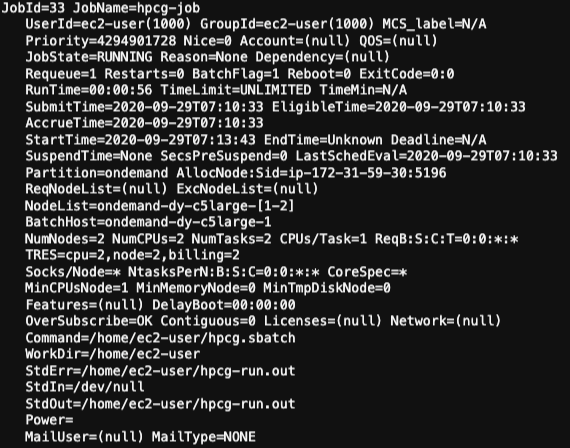
Now that you know how to submit jobs and check their details. Would you take the challenge of building a new submission script starting from job? Use the following command to upload your job script to one of your buckets when ready : aws s3 cp <path-to-local-file> s3://<YOUR_BUCKET>/<NAME_OF_YOUR_FILE> --acl public-read